Tldr; Your multimodal LLM places objects more realistically when it can extract finer scene geometry and visually verify placements.
Abstract
Scene generation with 3D assets presents a complex challenge, requiring both high-level semantic understanding and low-level geometric reasoning. While Multimodal Large Language Models (MLLMs) excel at semantic tasks, their application to 3D scene generation is hindered by their limited grounding on 3D geometry. In this paper, we investigate how to best work with MLLMs in an object placement task. Towards this goal, we introduce a novel framework, FirePlace, that applies existing MLLMs in (1) 3D geometric reasoning and the extraction of relevant geometric details from the 3D scene, (2) constructing and solving geometric constraints on the extracted low-level geometry, and (3) pruning for final placements that conform to common sense. By combining geometric reasoning with real-world understanding of MLLMs, our method can propose object placements that satisfy both geometric constraints as well as high-level semantic common-sense considerations. Our experiments show that these capabilities allow our method to place objects more effectively in complex scenes with intricate geometry, surpassing the quality of prior work.
What is FirePlace?
FirePlace is a multimodal LLM (MLLM) framework that generates object placements for new 3D objects you want inserted into your 3D scene, according to a language instruction. The input is (1) a 3D scene, (2) a 3D object, and (3) a text description of where the object should be placed. The output of Fireplace is an updated 3D scene with the object placed accordingly. Here's a few examples, with the inserted objects in red.

3 Challenges of Object Placement
1 Access to fine-grained geometry. Enabling realistic placements requires geometry information beyond bounding boxes. But how should geometric details be communicated to MLLMs? Prior works communicate bounding box parameters.
For instance,
teddy bear on the chair != BBOX_OF[teddy bear] on BBOX_OF[chair].


2 Contextual understanding of object instances. Objects that are placed into existing scenes need a way to tell different instances of identical objects apart, using the context in which they appear.
The left chair's occupied. So we should put the bear on the right chair.
3 Common-sense reasoning about placements. Placements that satisfy geometric constraints may not satisfy common sense reasoning about what's aesthetic, accessible or functional. These are hard to communicate using raw geometric constraints.
Of the 4 placements shown of a teddy bear on the chair, one of them makes the most "sense". You know because you can see them.

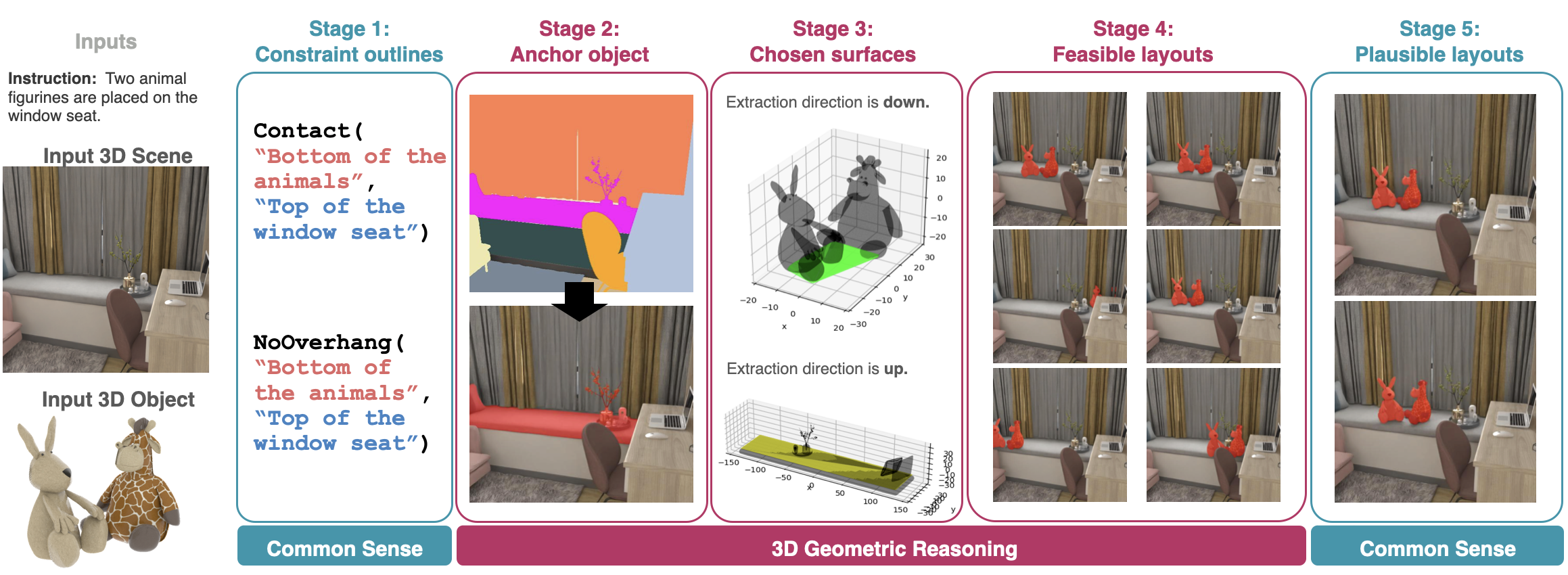
FirePlace's Approach
Given a 3D scene, an object, and a language input, FirePlace follows a five-stage process: (1) an MLLM generates a list of potential constraints, specifying relevant scene and object parts in natural language; (2) the MLLM resolves these references using Batched Visual Selection, our method of scaling inference compute to improve MLLM visual reasoning (read more in the paper!); (3) it calls geometric processing tools to extract convex hulls of interaction surfaces, which are then refined using Batched Visual Selection to ensure the right surfaces are used in the constraints; (4) mathematical constraints are formed and solved to determine geometrically valid placements; and (5) FirePlace renders these placements, selecting the best ones based on softer criteria like aesthetics, functionality, and accessibility.
Citation
If you found the paper useful, please cite: